Building Knowledge Graphs for RAG Systems with Neo4j & Google’s Gemini is a comprehensive exploration examines how knowledge graphs can significantly enhance Retrieval Augmented Generation (RAG) systems, as demonstrated in the google-neo4j-knowledge-graph-rag repository. The repository offers a structured approach to building knowledge graphs using Neo4j and integrating them with embedding models to improve the quality of text retrieval for language models. Through a series of well-designed notebooks, users can learn to construct, query, and leverage knowledge graphs to create more effective RAG systems that provide language models with highly relevant contextual information.
Introduction to Knowledge Graphs and RAG Systems
Knowledge graphs represent a powerful paradigm for organizing information in a way that captures relationships between entities, enabling more nuanced understanding and retrieval of data compared to traditional data structures. Retrieval Augmented Generation (RAG) systems combine the strengths of knowledge retrieval with generative language models to produce more accurate, contextually relevant outputs. The google-neo4j-knowledge-graph-rag repository demonstrates how these two technologies can be integrated to create more effective AI systems that understand and reason about complex information12.
Unlike traditional relational databases that store data in tables with predefined schemas, knowledge graphs organize information as entities (nodes) connected by relationships (edges), allowing for more flexible and intuitive representation of complex domains. This graph-based structure makes it particularly suitable for RAG systems, which need to retrieve relevant context based on semantic connections rather than just keyword matching. By leveraging the relational nature of knowledge graphs, RAG systems can retrieve information that is contextually connected to the query, even when the literal text might not contain the same keywords12.
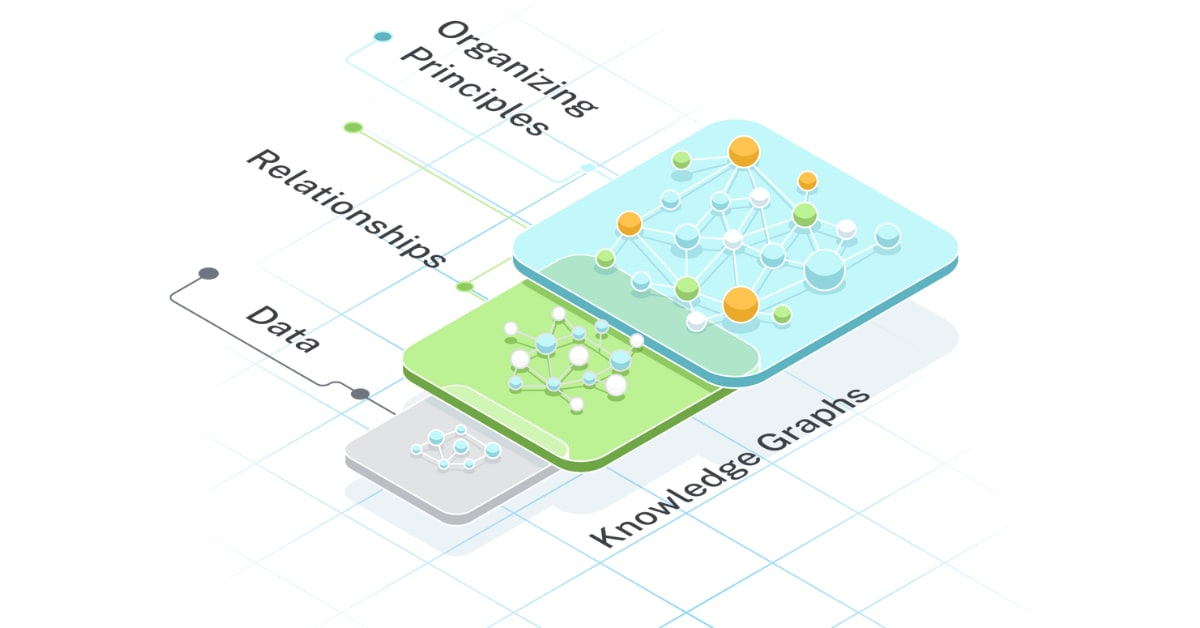
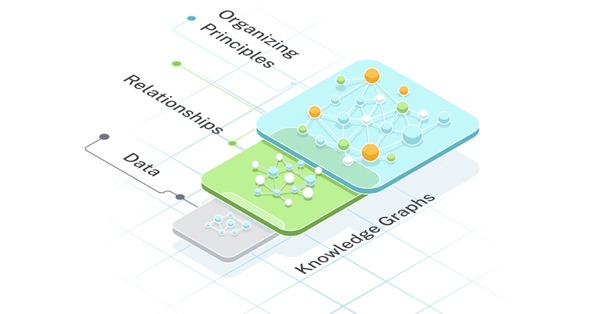
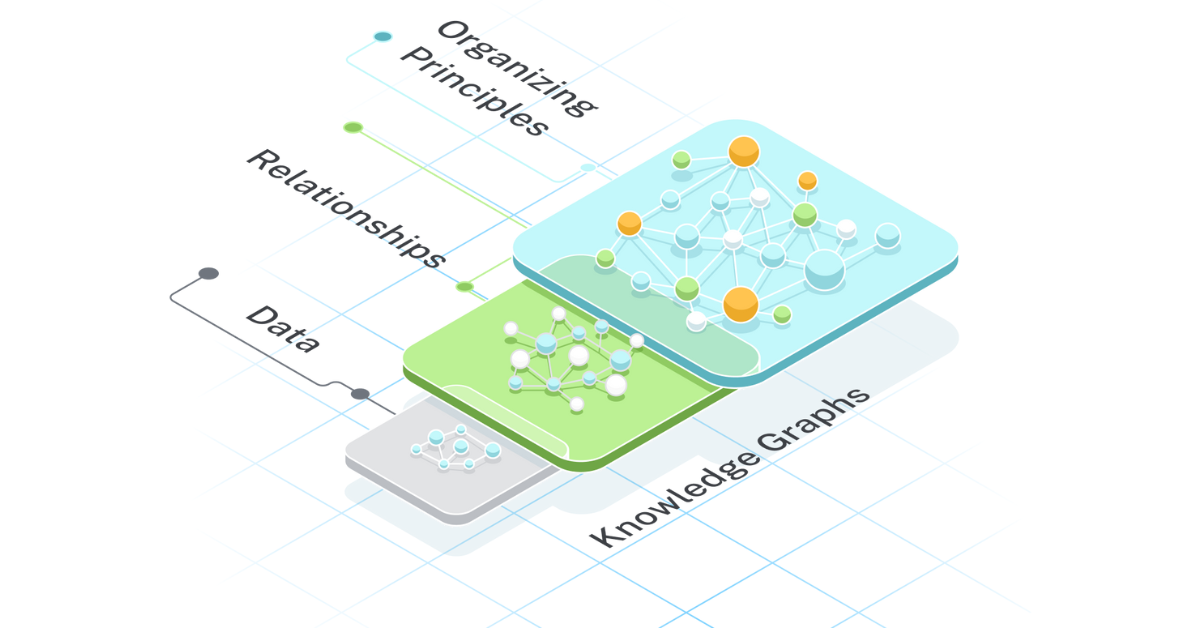 This image illustrates the fundamental structure of a knowledge graph, with nodes representing entities (like companies, people, or concepts) and edges representing the relationships between them. The graph demonstrates how information is connected in a way that preserves semantic meaning.
This image illustrates the fundamental structure of a knowledge graph, with nodes representing entities (like companies, people, or concepts) and edges representing the relationships between them. The graph demonstrates how information is connected in a way that preserves semantic meaning.
The Power of Neo4j for Knowledge Graph Construction
Neo4j, as the leading graph database platform, provides the foundation for building robust knowledge graphs in this repository. It offers a property graph model that allows for storing attributes on both nodes and relationships, making it ideal for representing rich, domain-specific information. The Cypher query language, specifically designed for graph databases, enables intuitive querying of complex patterns within the knowledge graph, which is essential for effective information retrieval in RAG systems12.
Repository Overview: A Structured Learning Path
The repository contains a carefully structured series of notebooks designed to guide users through the process of building and utilizing knowledge graphs for RAG systems. Each notebook focuses on a specific aspect of the knowledge graph lifecycle, from understanding the fundamental concepts to implementing advanced cross-document retrieval techniques12.
The learning path has been organized to progressively build skills, starting with foundational concepts and moving toward more advanced applications. This structured approach ensures that users can develop a solid understanding of both the theoretical underpinnings and practical implementations of knowledge graph-based RAG systems12.
 This image shows the organization of notebooks in the repository, highlighting the progressive learning path from basic concepts to advanced applications. The structure demonstrates how the repository guides users through a comprehensive learning journey.
This image shows the organization of notebooks in the repository, highlighting the progressive learning path from basic concepts to advanced applications. The structure demonstrates how the repository guides users through a comprehensive learning journey.
Introduction to Knowledge Graphs: Building a Foundation
The introductory notebooks provide essential background knowledge about graph databases and knowledge graphs. They explain the fundamental concepts of nodes, relationships, and properties, and demonstrate how these elements combine to create a semantic network that captures domain knowledge. These notebooks also compare knowledge graphs with traditional relational databases, highlighting the advantages of graph-based representations for certain types of data and queries12.
Users are introduced to the Neo4j graph database and its Cypher query language, which is specifically designed for working with graph data. Through practical examples, the notebooks demonstrate how to create, query, and visualize simple knowledge graphs, establishing the foundation for more complex applications in subsequent sections12.
 This visualization shows a simple knowledge graph created in Neo4j, demonstrating how entities and relationships are represented. The image highlights how graph visualization can make complex relationships more intuitive to understand compared to tabular data.
This visualization shows a simple knowledge graph created in Neo4j, demonstrating how entities and relationships are represented. The image highlights how graph visualization can make complex relationships more intuitive to understand compared to tabular data.
Building Knowledge Graphs from SEC Filings
The second set of notebooks focuses on practical knowledge graph construction, using SEC filings as a real-world data source. These notebooks guide users through the entire process, from data extraction and preprocessing to graph modeling and population1.
First, the notebooks demonstrate how to extract structured information from SEC filings, which are often semi-structured documents containing valuable financial and organizational data. Then, they show how to model this information as a graph, defining appropriate node types, relationship types, and properties to capture the domain semantics effectively1.
Using Neo4j’s data import tools, the notebooks guide users through the process of populating the knowledge graph with the extracted information. They also cover techniques for validating and refining the graph structure to ensure it accurately represents the domain knowledge contained in the SEC filings1.
 This diagram illustrates the workflow for transforming SEC filings into a knowledge graph. It shows the progression from document extraction, through entity and relationship identification, to final graph construction in Neo4j.
This diagram illustrates the workflow for transforming SEC filings into a knowledge graph. It shows the progression from document extraction, through entity and relationship identification, to final graph construction in Neo4j.
Advanced Graph Modeling Techniques
The notebooks in this section delve deeper into graph modeling techniques, showing how to represent complex relationships between financial entities such as companies, executives, subsidiaries, and financial metrics. They demonstrate how to capture temporal aspects of the data, such as changes in company structure or financial performance over time, which is critical for accurate analysis of SEC filings1.
Additionally, the notebooks cover techniques for enriching the knowledge graph with external data sources, such as industry classifications, geographic information, or market data. This enrichment process creates a more comprehensive representation of the domain, enabling more sophisticated queries and analyses1.
Integrating Knowledge Graphs into RAG Systems
The third set of notebooks focuses on integrating the constructed knowledge graph into a Retrieval Augmented Generation system. These notebooks demonstrate how to use Langchain, a framework for developing applications with language models, to connect the knowledge graph with generative AI models12.
The integration process involves several key components. First, the notebooks show how to create embeddings for the nodes and relationships in the knowledge graph, which enables semantic search capabilities. Then, they demonstrate how to design and implement retrieval strategies that leverage both the graph structure and the semantic embeddings to find the most relevant information for a given query12.
 This architectural diagram illustrates how knowledge graphs fit into a RAG system. It shows the flow from user query through graph retrieval and into language model generation, highlighting the role of Neo4j and Langchain in this process.
This architectural diagram illustrates how knowledge graphs fit into a RAG system. It shows the flow from user query through graph retrieval and into language model generation, highlighting the role of Neo4j and Langchain in this process.
Enhancing RAG with Graph-based Retrieval
The notebooks explore various techniques for enhancing the retrieval process using graph-based approaches. They demonstrate how to use graph algorithms such as shortest path, community detection, and centrality measures to identify relevant information that might not be found through traditional keyword or embedding-based retrieval methods12.
Furthermore, the notebooks show how to combine graph-based retrieval with embedding-based retrieval to create hybrid approaches that leverage the strengths of both methods. This hybrid approach can significantly improve the relevance and completeness of the retrieved information, leading to better inputs for the language model and ultimately higher quality generated outputs12.
Advanced Techniques: Cross-Document Knowledge Integration
The advanced notebooks take the knowledge graph approach to the next level by building multiple knowledge graphs from different document sets and connecting them through linking data. This approach enables cross-document queries and retrieval, which is particularly valuable for complex analysis scenarios involving multiple sources of information12.
The notebooks guide users through the process of identifying common entities across different document sets, establishing links between these entities, and merging the separate knowledge graphs into a unified representation. They also demonstrate advanced graph query techniques that can traverse these links to retrieve relevant information across multiple documents, providing a more comprehensive view of the domain12.
 This visualization demonstrates how separate knowledge graphs built from different document sets can be connected through shared entities. The connections enable cross-document querying and provide a more comprehensive view of the domain knowledge.
This visualization demonstrates how separate knowledge graphs built from different document sets can be connected through shared entities. The connections enable cross-document querying and provide a more comprehensive view of the domain knowledge.
Practical Applications of Cross-Document Knowledge Graphs
The advanced techniques section explores practical applications of cross-document knowledge graphs, such as analyzing relationships between companies in the same industry, tracking changes in corporate structures over time, or investigating complex financial networks. These applications demonstrate the power of knowledge graphs for uncovering insights that would be difficult or impossible to obtain using traditional document retrieval methods12.
The notebooks also discuss strategies for scaling these approaches to handle larger document collections and more complex domains. They explore techniques such as graph partitioning, distributed processing, and incremental updates that can help maintain performance and manageability as the knowledge graph grows12.
Benefits and Practical Applications
By completing the notebooks in this repository, users gain a range of valuable skills and capabilities that can be applied to various real-world scenarios. They learn to construct knowledge graphs that accurately represent domain-specific information, design effective retrieval strategies that leverage both graph structure and semantics, and integrate these components into RAG systems that produce high-quality outputs12.
The approach demonstrated in this repository has several advantages over traditional document retrieval methods. By capturing the relationships between entities, knowledge graphs enable more precise and contextually relevant retrieval. They can answer complex questions that require connecting information across multiple documents or understanding implicit relationships. And they provide a more intuitive way to explore and visualize complex domains, making it easier to identify patterns and insights12.
 This chart compares the performance of traditional RAG systems with knowledge graph-enhanced RAG systems across various metrics such as relevance, completeness, and accuracy. The visualization highlights the quantitative improvements that can be achieved by incorporating knowledge graphs.
This chart compares the performance of traditional RAG systems with knowledge graph-enhanced RAG systems across various metrics such as relevance, completeness, and accuracy. The visualization highlights the quantitative improvements that can be achieved by incorporating knowledge graphs.
Conclusion: The Future of Knowledge-Enhanced AI
The google-neo4j-knowledge-graph-rag repository represents an important step toward more knowledgeable and contextually aware AI systems. By combining the structural advantages of knowledge graphs with the semantic power of embeddings and the generative capabilities of language models, this approach creates RAG systems that can retrieve and reason about complex information in more sophisticated ways12.
As AI continues to evolve, the ability to effectively represent, retrieve, and reason with knowledge will become increasingly important. The techniques demonstrated in this repository provide a foundation for building AI systems that can understand and work with complex domains, making them valuable tools for researchers, developers, and organizations seeking to leverage the full potential of AI for knowledge-intensive tasks12.
The repository empowers users to develop more intelligent RAG systems that can retrieve precisely relevant information across extensive document collections, ultimately enhancing the quality and accuracy of AI-generated outputs through better context retrieval and knowledge utilization12.
